Mar 21, 2024 | By

Before diving deep into the details of YOLO, Let’s look at some basic terminologies in computer vision.
Single Object

Multiple Object

Hope you got the basic terms right. Now let's start understanding YOLO.
YOLO stands for You Only Look Once, it is a state-of-the-art algorithm used for object detection tasks. YOLO stands out from its competitors like RCNN, and Faster RCNN because of its simple architecture (enabling high speed) and high accuracy.
Before looking at the working model of YOLO, we will first try to understand how object localization actually works.
Working of Object localization:
Using a neural network for object localization task results output vector as below :
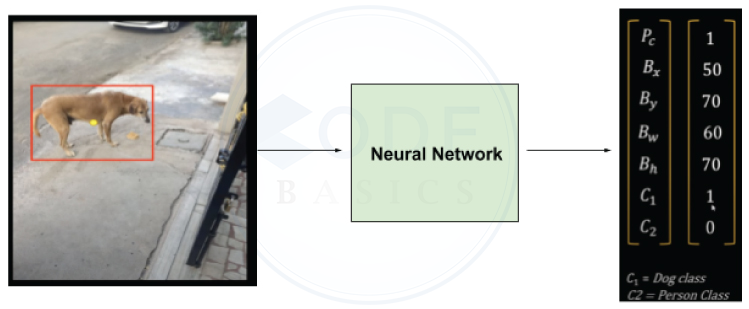
Without worrying much about the neural network architecture used, let’s try to understand what the output vector represents.
Here output vector size is 7 with the below indications.
Pc indicates whether any object of interest is there or not in the image
Bx to Bh indicates bounding box coordinates
C1 will be 1 if the object detected is a dog otherwise it will be 0
C2 will be 1 if the object detected is a person otherwise it will be 0
So for training, we should give images with bounding boxes as x_train and its corresponding output vector as y_train for the neural network.
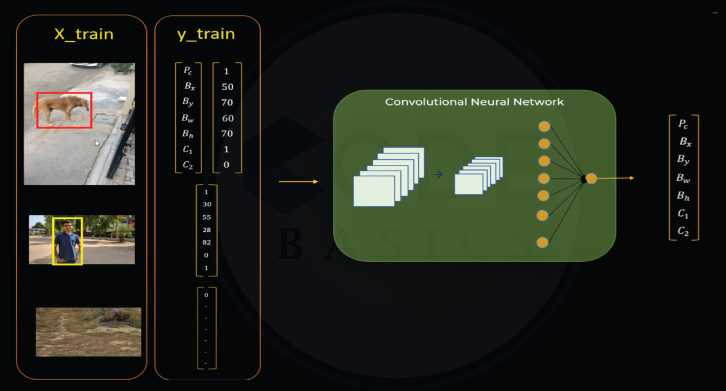
As mentioned above, many images with their ground truth vectors will be fed into the neural net.
When we pass a new image to the trained neural net it will predict the class of the object and its position as below.

As C1 in the output vector is 1, the object predicted is of class dog and its coordinates are predicted as [25,57,30,42]
This method looks perfectly fine. Wait !! What if an image contains multiple objects ??
Then how do we decide on output vector size? One possible way could be, let’s say our image has n objects then the output vector of size n * 7 will solve the problem.
Here is the catch, we don’t know how many objects will be there in an image. As n is unknown we can’t use this technique for images with multiple objects.
Object detection models are the savior. Let’s see how they solve this problem. Let’s say we have an image with two objects (a dog and a person) as below.

What YOLO will do?
Step 1: Divides the image into grids
Step 2: Mark the center of each object
Step 3: Generates the output vector for each grid formed.
Let's say we are using a 4 x 4 grid

Grids without any objects will be just marked with empty vectors as below.

How the output vector will be derived if a particular grid contains multiple objects?
Let’s consider this grid below. Here the model uses the object's center for tagging the grid into a particular class. As this grid contains a dog's center it will be treated as an object of dog class.

This is how YOLO generates output vectors of size 7 for each grid. So for our image with 4 x 4 grid , we will get 4 x 4 x 7 vectors. This will be fed into a neural net for training.

After training, when the neural net is given a new object it generates output with 16 x 7 vectors.
Which then be used for classification and bounding box regression.
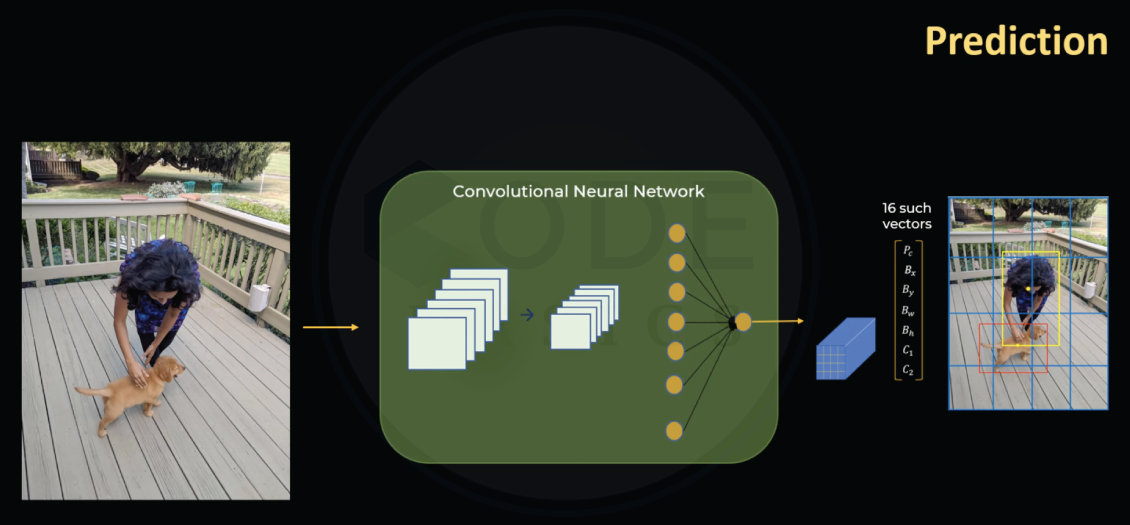
As the name suggests it performs classification and bounding box regression at the same time unlike other architectures like RCNN.
Issues with this approach :
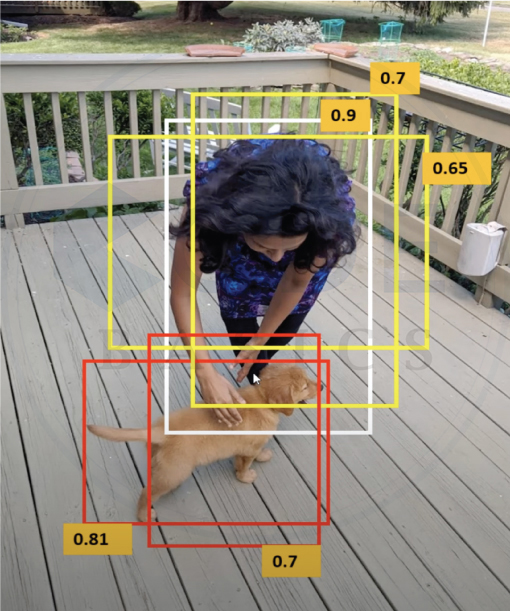
1. Multiple bounding boxes
The model can draw multiple bounding boxes with a probability associated with each entity to make predictions accurate. Ideally, we need a single bounding box for each object in the image as shown on the right.
One could think of considering only the box with the highest probability score and removing others will solve this problem.
However, we can’t do this because let’s say we have two objects of class “Person” in an image with different probability scores. Removing the one with low confidence will not capture one of the person's objects.
So, to solve this problem we have something called the Non-Max suppression technique.
Non-Max Suppression :
As the name suggests, this technique is to suppress all the unnecessary bounding boxes and to keep only the best one.
It considers two things :
 |
 |
- Probability score associated with each bounding box (This indicates the confidence level of the model in predicting whether an object is present in the box marked or not)
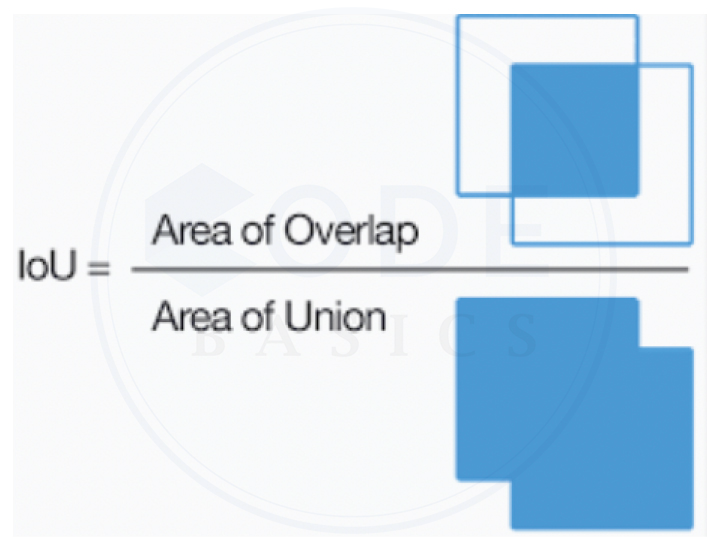
- IOU (Intersection Over Union)
IOU is the most popular metric used to measure the extent of overlap between two boxes. It is simply calculated as Area of Overlap / Area of Union.
Non-Max suppression will first select the bounding box with a high probability score and then calculates IOU of the selected bounding box with the other ones. By keeping some threshold for IOU, it will remove all the boxes which got an IOU score of more than a threshold value.
This is how Non-Max suppression helps in removing redundant bounding boxes.
| Before Non-Max Suppression | After Non-Max Suppression | ||
|
|

2. Single grid with multiple centers
What if a single grid contains more than one object’s center? something like below

In the above image, lower center grid contains the midpoints of both a person and a car. In this case, the algorithm generates two anchor boxes and forms the output vector as below.
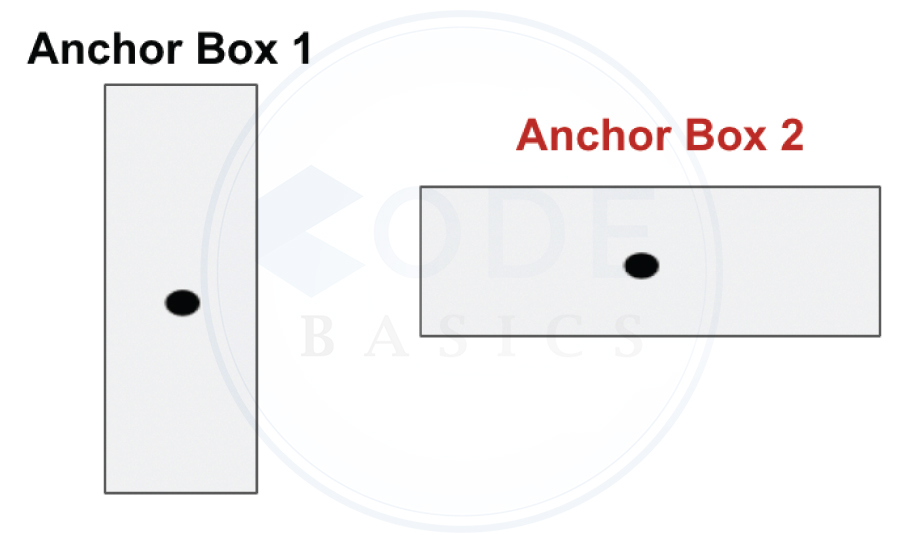

Output vector size transformation : 4 x 4 x 7 → 4 x 4 x (2 x 7)
Problems still not solved by YOLO:
-
What if a single grid contains more than two midpoints of objects of interest?
-
What if two midpoints falling in a single grid have similar anchor box shapes?
In real-time, we usually use more grids to divide the image (Unlike in the examples above, we have seen 4 x 4 grids) so the chances of midpoints overlapping in the same grid are very less.
That’s pretty much about YOLO and it’s working. Hope you enjoyed learning it.
/308538/Bootcamp/thumbnail_bootcamp_2.0.webp)
Related Blogs
/fit-in/500x500/308538/Blogs/Machine_20Learning_20101-01.webp)
/fit-in/500x500/images/1.1.419/blogs/thumbnails/what-is-a-neural-network.webp)
Mar 26, 2024
What is a Neural Network?/fit-in/500x500/images/1.1.419/blogs/thumbnails/why-deep-learning-is-becoming-so-popular.webp)
Mar 21, 2024
Why Deep Learning is becoming so popular? Log in with Google
Log in with Google Log in with Linkedin
Log in with Linkedin